Hash 基礎
#clippings
unordered_map => 無序,key不可重複,優先使用。
set => 有序,key不可重複。
multiset => 有序,key可重複。
哈希表
首先什麼是 哈希表,哈希表(英文名字為Hash table,國內也有一些算法書籍翻譯為雜湊表,大家看到這兩個名稱知道都是指hash table就可以了)。
哈希表是根據關鍵碼的值而直接進行訪問的數據結構。
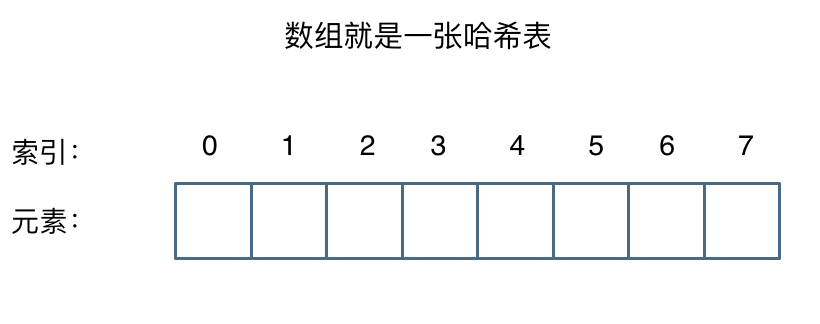
這麼這官方的解釋可能有點懵,其實直白來講其實數組就是一張哈希表。
哈希表中關鍵碼就是數組的索引下標,然後通過下標直接訪問數組中的元素,如下圖所示:
那麼哈希表能解決什麼問題呢,一般哈希表都是用來快速判斷一個元素是否出現集合裡。
例如要查詢一個名字是否在這所學校裡。
要枚舉的話時間複雜度是O(n),但如果使用哈希表的話, 只需要O(1)就可以做到。
我們只需要初始化把這所學校裡學生的名字都存在哈希表裡,在查詢的時候通過索引直接就可以知道這位同學在不在這所學校裡了。
將學生姓名映射到哈希表上就涉及到了hash function ,也就是哈希函數。
哈希函數
哈希函數,把學生的姓名直接映射為哈希表上的索引,然後就可以通過查詢索引下標快速知道這位同學是否在這所學校裡了。
哈希函數如下圖所示,通過hashCode把名字轉化為數值,一般hashcode是通過特定編碼方式,可以將其他數據格式轉化為不同的數值,這樣就把學生名字映射為哈希表上的索引數字了。
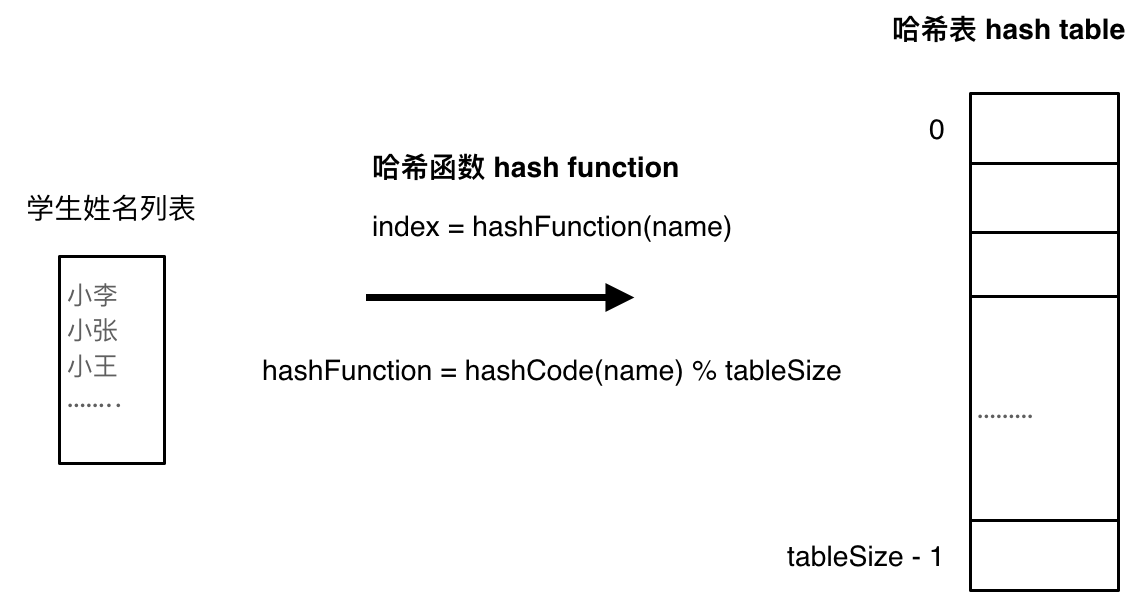
如果hashCode得到的數值大於 哈希表的大小了,也就是大於tableSize了,怎麼辦呢?
此時為了保證映射出來的索引數值都落在哈希表上,我們會在再次對數值做一個取模的操作,就要我們就保證了學生姓名一定可以映射到哈希表上了。
此時問題又來了,哈希表我們剛剛說過,就是一個數組。
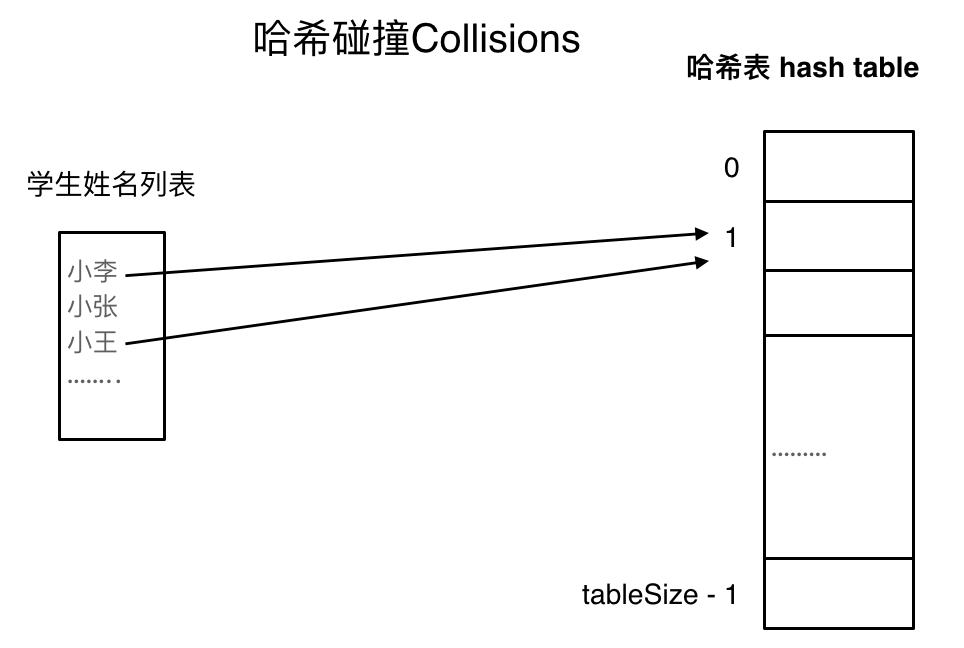
如果學生的數量大於哈希表的大小怎麼辦,此時就算哈希函數計算的再均勻,也避免不了會有幾位學生的名字同時映射到哈希表 同一個索引下標的位置。
接下來哈希碰撞登場
哈希碰撞
如圖所示,小李和小王都映射到了索引下標 1 的位置,這一現象叫做哈希碰撞。
一般哈希碰撞有兩種解決方法, 拉鍊法和線性探測法。
拉鍊法
剛剛小李和小王在索引1的位置發生了衝突,發生衝突的元素都被存儲在鏈表中。 這樣我們就可以通過索引找到小李和小王了
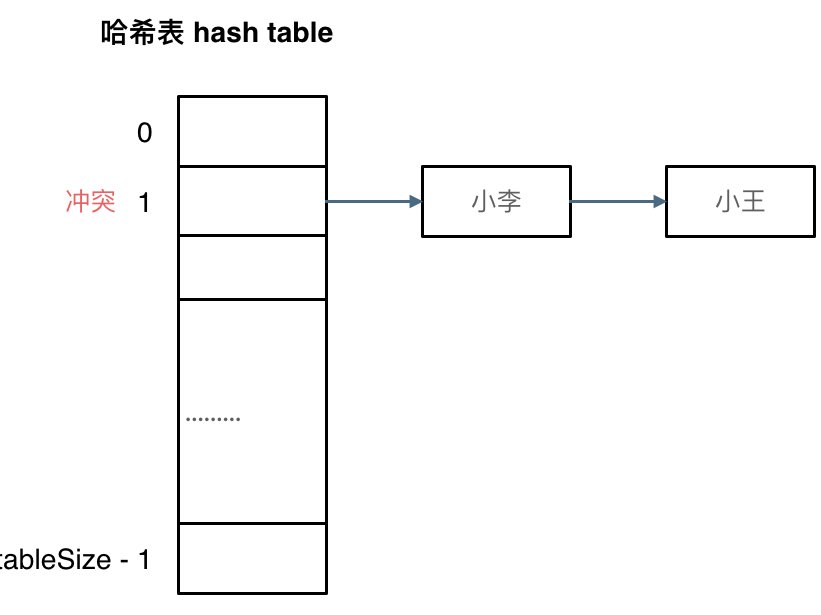
(數據規模是dataSize, 哈希表的大小為tableSize)
其實拉鍊法就是要選擇適當的哈希表的大小,這樣既不會因為數組空值而浪費大量內存,也不會因為鏈表太長而在查找上浪費太多時間。
線性探測法
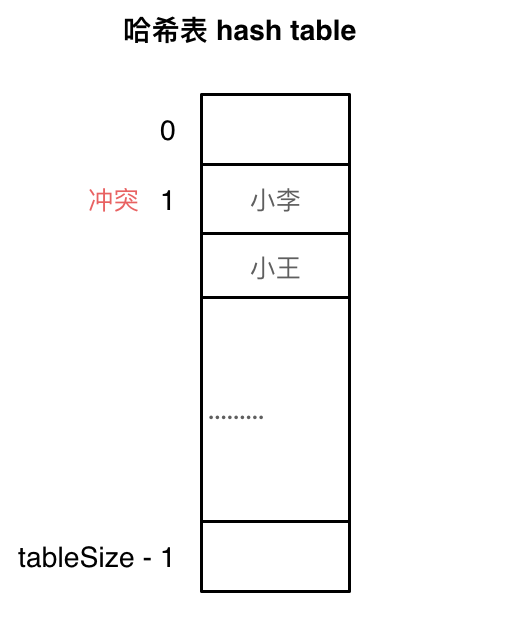
使用線性探測法,一定要保證tableSize大於dataSize。 我們需要依靠哈希表中的空位來解決碰撞問題。
例如衝突的位置,放了小李,那麼就向下找一個空位放置小王的信息。所以要求tableSize一定要大於dataSize ,要不然哈希表上就沒有空置的位置來存放 衝突的數據了。如圖所示:
其實關於哈希碰撞還有非常多的細節,感興趣的同學可以再好好研究一下,這裡我就不再贅述了。
常見的三種哈希結構
當我們想使用哈希法來解決問題的時候,我們一般會選擇如下三種數據結構。
- 數組
- set (集合)
- map (映射)
這裡數組就沒啥可說的了,我們來看一下set。
在C++中,set 和 map 分別提供以下三種數據結構,其底層實現以及優劣如下表所示:
| 集合 | 底層實現 | 是否有序 | 數值是否可以重複 | 能否更改數值 | 查詢效率 | 增刪效率 |
|---|---|---|---|---|---|---|
| std::set | 紅黑樹 | 有序 | 否 | 否 | O(log n) | O(log n) |
| std::multiset | 紅黑樹 | 有序 | 是 | 否 | O(logn) | O(logn) |
| std::unordered_set | 哈希表 | 無序 | 否 | 否 | O(1) | O(1) |
std::unordered_set底層實現為哈希表,std::set 和std::multiset 的底層實現是紅黑樹,紅黑樹是一種平衡二叉搜索樹,所以key值是有序的,但key不可以修改,改動key值會導致整棵樹的錯亂,所以只能刪除和增加。
| 映射 | 底層實現 | 是否有序 | 數值是否可以重複 | 能否更改數值 | 查詢效率 | 增刪效率 |
|---|---|---|---|---|---|---|
| std::map | 紅黑樹 | key有序 | key不可重複 | key不可修改 | O(logn) | O(logn) |
| std::multimap | 紅黑樹 | key有序 | key可重複 | key不可修改 | O(log n) | O(log n) |
| std::unordered_map | 哈希表 | key無序 | key不可重複 | key不可修改 | O(1) | O(1) |
std::unordered_map 底層實現為哈希表,std::map 和std::multimap 的底層實現是紅黑樹。同理,std::map 和std::multimap 的key也是有序的(這個問題也經常作為面試題,考察對語言容器底層的理解)。
當我們要使用集合來解決哈希問題的時候,優先使用unordered_set,因為它的查詢和增刪效率是最優的,如果需要集合是有序的,那麼就用set,如果要求不僅有序還要有重複數據的話,那麼就用multiset。
那麼再來看一下map ,在map 是一個key value 的數據結構,map中,對key是有限製,對value沒有限製的,因為key的存儲方式使用紅黑樹實現的。
其他語言例如:java裡的HashMap ,TreeMap 都是一樣的原理。可以靈活貫通。
雖然std::set、std::multiset 的底層實現是紅黑樹,不是哈希表,std::set、std::multiset 使用紅黑樹來索引和存儲,不過給我們的使用方式,還是哈希法的使用方式,即key和value。所以使用這些數據結構來解決映射問題的方法,我們依然稱之為哈希法。 map也是一樣的道理。
這裡在說一下,一些C++的經典書籍上 例如STL源碼剖析,說到了hash_set hash_map,這個與unordered_set,unordered_map又有什麼關係呢?
實際上功能都是一樣一樣的, 但是unordered_set在C++11的時候被引入標準庫了,而hash_set並沒有,所以建議還是使用unordered_set比較好,這就好比一個是官方認證的,hash_set,hash_map 是C++11標準之前民間高手自發造的輪子。