內存管理
source:: 刷了这么多题,你了解自己代码的内存消耗么? | 代码随想录
#clippings
理解代碼的內存消耗,最關鍵是要知道自己所用編程語言的內存管理。
不同語言的內存管理
不同的編程語言各自的內存管理方式。
- C/C++這種內存堆空間的申請和釋放完全靠自己管理
- Java 依賴JVM來做內存管理,不瞭解jvm內存管理的機制,很可能會因一些錯誤的代碼寫法而導致內存泄漏或內存溢出
- Python內存管理是由私有堆空間管理的,所有的python對象和數據結構都存儲在私有堆空間中。程序員沒有訪問堆的權限,只有解釋器才能操作。
例如Python萬物皆對象,並且將內存操作封裝的很好,所以python的基本數據類型所用的內存會要遠大於存放純數據類型所占的內存,例如,我們都知道存儲int型數據需要四個字節,但是使用Python 申請一個對象來存放數據的話,所用空間要遠大於四個字節。
C++的內存管理
以C++為例來介紹一下編程語言的內存管理。
如果我們寫C++的程序,就要知道棧和堆的概念,程序運行時所需的內存空間分為 固定部分,和可變部分,如下:
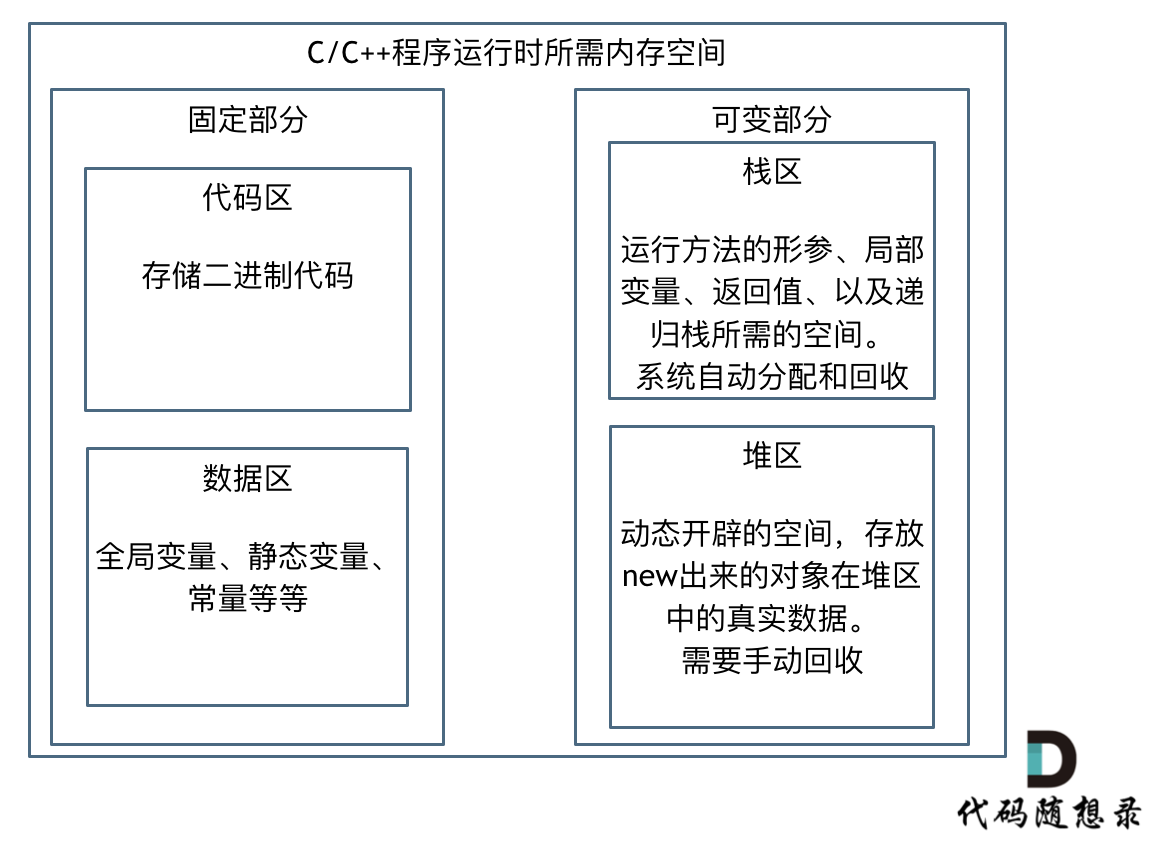
固定部分的內存消耗 是不會隨著代碼運行產生變化的, 可變部分則是會產生變化的
更具體一些,一個由C/C++編譯的程序占用的內存分為以下幾個部分:
- 棧區(Stack) :由編譯器自動分配釋放,存放函數的參數值,局部變量的值等,其操作方式類似於數據結構中的棧。
- 堆區(Heap) :一般由程序員分配釋放,若程序員不釋放,程序結束時可能由OS收回
- 未初始化數據區(Uninitialized Data): 存放未初始化的全局變量和靜態變量
- 初始化數據區(Initialized Data):存放已經初始化的全局變量和靜態變量
- 程序代碼區(Text):存放函數體的二進制代碼
代碼區和數據區所占空間都是固定的,而且占用的空間非常小,那麼看運行時消耗的內存主要看可變部分。
在可變部分中,棧區間的數據在代碼塊執行結束之後,系統會自動回收,而堆區間數據是需要程序員自己回收,所以也就是造成內存泄漏的發源地。
而Java、Python的話則不需要程序員去考慮內存泄漏的問題,虛擬機都做了這些事情。
如何計算程序占用多大內存
想要算出自己程序會占用多少內存就一定要瞭解自己定義的數據類型的大小,如下:

注意圖中有兩個不一樣的地方,為什麼64位的指針就占用了8個字節,而32位的指針占用4個字節呢?
1個字節占8個比特,那麼4個字節就是32個比特,可存放數據的大小為2^32,也就是4G空間的大小,即:可以尋找4G空間大小的內存地址。
大家現在使用的計算機一般都是64位了,所以編譯器也都是64位的。
安裝64位的操作系統的計算機內存都已經超過了4G,也就是指針大小如果還是4個字節的話,就已經不能尋址全部的內存地址,所以64位編譯器使用8個字節的指針才能尋找所有的內存地址。
注意2^64是一個非常巨大的數,對於尋找地址來說已經足夠用了。
內存對齊
再介紹一下內存管理中另一個重要的知識點:內存對齊。
不要以為只有C/C++才會有內存對齊,只要可以跨平台的編程語言都需要做內存對齊,Java、Python都是一樣的。
而且這是面試中面試官非常喜歡問到的問題,就是:為什麼會有內存對齊?
主要是兩個原因
平台原因:不是所有的硬件平台都能訪問任意內存地址上的任意數據,某些硬件平台只能在某些地址處取某些特定類型的數據,否則拋出硬件異常。為了同一個程序可以在多平台運行,需要內存對齊。
硬件原因:經過內存對齊後,CPU訪問內存的速度大大提升。
可以看一下這段C++代碼輸出的各個數據類型大小是多少?
struct node{
int num;
char cha;
}st;
int main() {
int a[100];
char b[100];
cout << sizeof(int) << endl;
cout << sizeof(char) << endl;
cout << sizeof(a) << endl;
cout << sizeof(b) << endl;
cout << sizeof(st) << endl;
}
看一下和自己想的結果一樣麼, 我們來逐一分析一下。
其輸出的結果依次為:
此時會發現,和單純計算字節數的話是有一些誤差的。
這就是因為內存對齊的原因。
來看一下內存對齊和非內存對齊產生的效果區別。
CPU讀取內存不是一次讀取單個字節,而是一塊一塊的來讀取內存,塊的大小可以是2,4,8,16個字節,具體取多少個字節取決於硬件。
假設CPU把內存劃分為4字節大小的塊,要讀取一個4字節大小的int型數據,來看一下這兩種情況下CPU的工作量:
第一種就是內存對齊的情況,如圖:
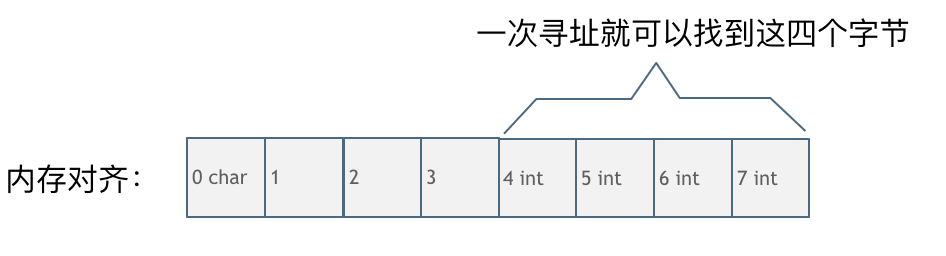
一字節的char占用了四個字節,空了三個字節的內存地址,int數據從地址4開始。
此時,直接將地址4,5,6,7處的四個字節數據讀取到即可。
第二種是沒有內存對齊的情況如圖:
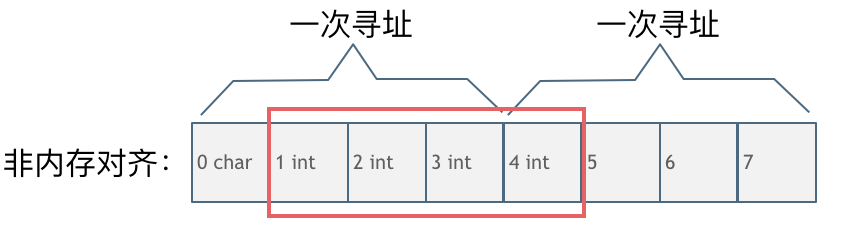
char型的數據和int型的數據挨在一起,該int數據從地址1開始,那麼CPU想要讀這個數據的話來看看需要幾步操作:
- 因為CPU是四個字節四個字節來尋址,首先CPU讀取0,1,2,3處的四個字節數據
- CPU讀取4,5,6,7處的四個字節數據
- 合併地址1,2,3,4處四個字節的數據才是本次操作需要的int數據
此時一共需要兩次尋址,一次合併的操作。
大家可能會發現內存對齊豈不是浪費的內存資源麼?
是這樣的,但事實上,相對來說計算機內存資源一般都是充足的,我們更希望的是提高運行速度。
編譯器一般都會做內存對齊的優化操作,也就是說當考慮程序真正占用的內存大小的時候,也需要認識到內存對齊的影響。